Don’t communicate by sharing memory; share memory by communicating.
라길래, channel과 mutex의 성능을 알아봤다.
테스트 머신은 Xeon CPU가 두 개 달렸고, 12G의 램을 가지고 있다. 각 CPU당 6개의 코어가 있으므로, 하이퍼쓰레딩을 이용하여 최대 24개의 코어를 사용할 수 있다.
테스트는 channel을 사용하는 경우와 mutex를 사용하는 경우로 나눴으며, 10번의 결과를 평균내어 최종 결론을 만든다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
package main import ( "flag" "fmt" "math/rand" "runtime" "sync" "time" ) type Request struct { Id int ResChan chan Response } type Response struct { Id int Value int } func benchMessage(clientNum int) time.Duration { sharedValue := 0 var wg sync.WaitGroup start := time.Now() reqChan := make(chan Request, 100) go func() { for { req := <-reqChan sharedValue++ req.ResChan <- Response{Id: req.Id, Value: sharedValue} } }() for i := 0; i < clientNum; i++ { wg.Add(1) go func(index int) { defer wg.Done() c := make(chan Response) defer close(c) id := rand.Int() reqChan <- Request{Id: id, ResChan: c} <-c }(i) } wg.Wait() elapsed := time.Since(start) return elapsed } func benchMutex(clientNum int) time.Duration { sharedValue := 0 var wg sync.WaitGroup start := time.Now() mutex := &sync.Mutex{} for i := 0; i < clientNum; i++ { wg.Add(1) go func(index int) { defer wg.Done() mutex.Lock() sharedValue++ mutex.Unlock() }(i) } wg.Wait() elapsed := time.Since(start) return elapsed } func main() { clientNum := flag.Int("client", 500000, "Number of clients") repeatCount := flag.Int("repeat", 10, "Repeat count") flag.Parse() rand.Seed(time.Now().UnixNano()) cores := [...]int{1, 2, 4, 8, 16} for _, coreNum := range cores { runtime.GOMAXPROCS(coreNum) var messageTotalElapsed time.Duration var mutexTotalElapsed time.Duration for i := 0; i < *repeatCount; i++ { messageTotalElapsed += benchMessage(*clientNum) mutexTotalElapsed += benchMutex(*clientNum) } fmt.Println("cores:", coreNum, "message:", messageTotalElapsed/time.Duration(*repeatCount), "mutex:", mutexTotalElapsed/time.Duration(*repeatCount)) } } |
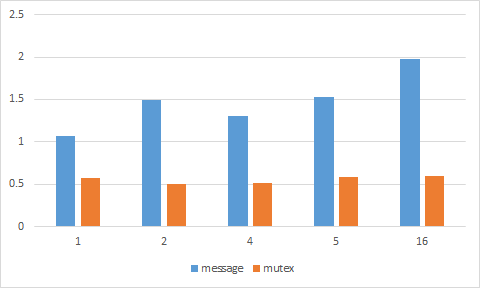
아래의 그래프가 그 결과로, 사용하는 코어의 개수와 관계없이 channel을 사용하는 것이 mutex를 사용하는 것보다 느리다는 것을 알려준다.
추가로 테스트 한 바, channel의 크기를 변경하는 것은 결과에 별다른 영향을 미치지 못한다.
Go로 프로그래밍 할 경우, channel을 사용할지 mutex를 사용할지에 대한 조언은 여기에 좀 더 자세히 나와있다.